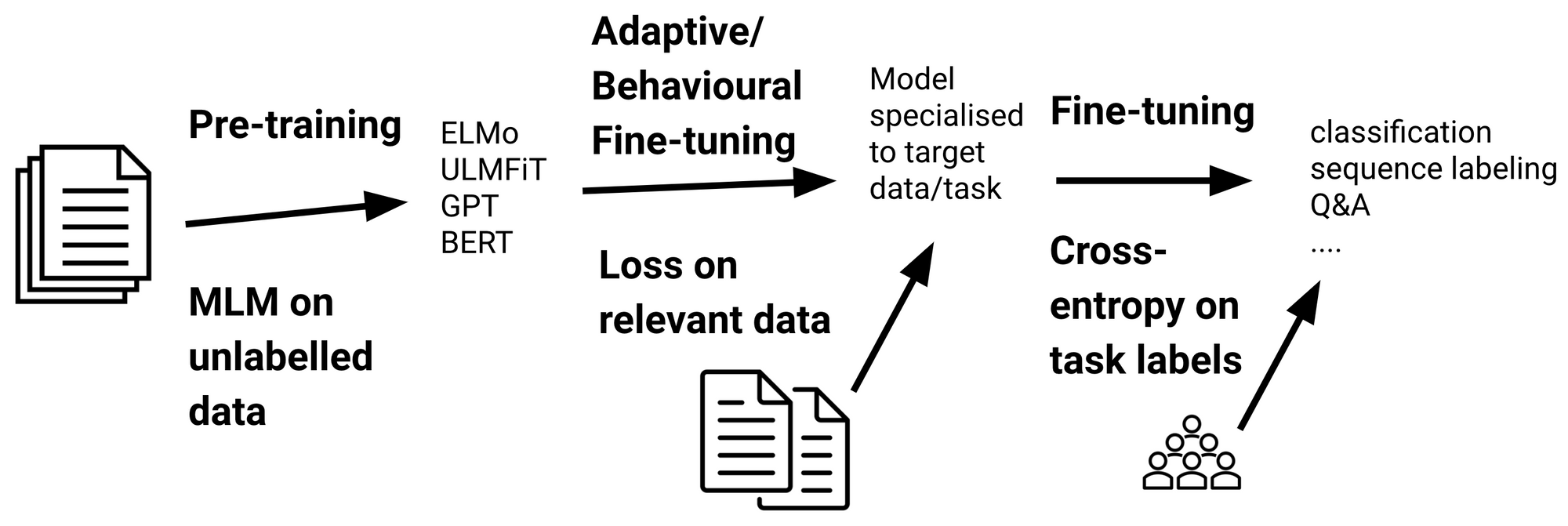




들어가며
KcBERT를 공개하며 NSMC를 예제로 PyTorch-Lightning을 이용한 Downstream task Fine-tune을 진행하는 Colab 예제(링크, 새 창)를 만들어 배포해보았다.
한편, Transformers의 버전과 PyTorch-Lightning, 그리고 PyTorch의 버전 자체가 올라가면서 여러가지의 기능이 추가되고, 여러 함수나 내장 세팅 등이 꽤나 많이 Deprecated되었다.
사람은 언제나 귀찮음에 지배되기 때문에 코드를 한번 만들고 최소한의 수정만을 하면서 ‘돌아가기는 하는’ 수준으로 코드를 유지했다.
하지만 실행시마다 뜨는 ‘Deprecate warnings’에 질리는 순간이 오고, 지금이 바로 그 순간이라 기존 코드를 “보다 좋게”, 그리고 기왕 수정하는 김에 모델 체크포인트 저장(성능에 따른) / Logging 서비스 연동 / Inference 코드 추가를 진행해보면 어떨까 싶다.
이 글은 이 Colab 노트북(링크) 에서 직접 실행해 보실 수 있습니다.

