2018년말부터 현재까지 NLP 연구에서 BERT는 여전히 압도적인 위치를 차지하고 있다.
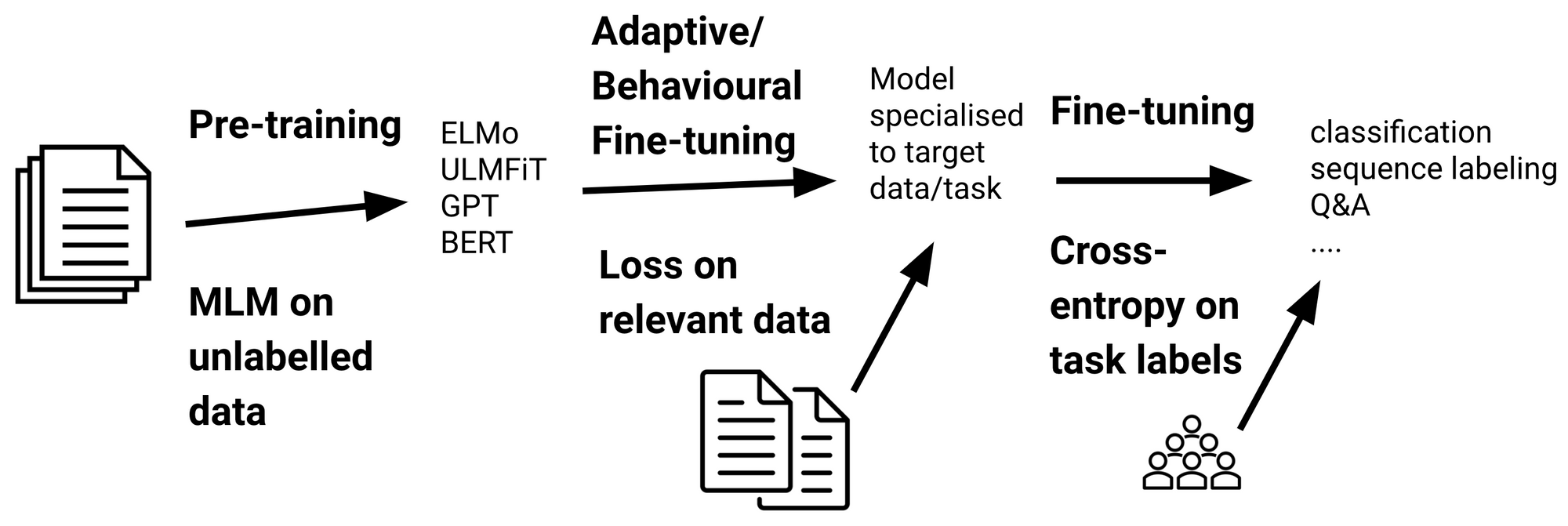
한편, BERT모델을 사용하는 이유 중 가장 큰 것 하나가 바로 한국어로 Pretrained된 모델이 있다는 점이다. Google에서 논문을 처음 공개했을 때 Multilingual pretrained model을 공개해 Fine-tuning만으로도 우리가 필요한 데이터셋에 맞춰 분류기를 만드는 등의 여러 응용이 가능하고, 동시에 높은 성능을 보여주었기 때문에 BERT 자체를 학습시키는 것에 대해서는 크게 신경쓰지 않은 것이 사실이다.
한편 작년 ETRI의 한국어 BERT 언어모델, 그리고 SKTBrain의 KoBERT 등 한국어 데이터셋으로 학습시킨 모델들이 등장했고, 이런 모델들을 Fine-tuning할 경우 기존 구글의 다국어 모델을 사용한 것보다 성능이 조금이라도 더 잘 나오기도 한다. (특히 정제되지 않은 글에 대해 좀 더 나은 성능을 보여줬다. OOV문제가 덜한 편이었다.)
다만 이런 모델들 역시 굉장히 ‘보편적’ 글로 학습된 것이라 도메인 특화된 분야에 있어서는 성능이 잘 나오지 않을 수도 있다. 따라서 특수한 경우의 특수한 도메인에 최적화된 Pretrained model을 만든다면 우리의 NLP 모델도 좀 더 성능이 좋아질 수 있다!
이번 글에서는 BERT 모델을 TPU와 Tensorflow를 이용해 처음부터 학습시켜보는 과정을 다뤄본다.
이번 글은 Colab Notebook: Pre-training BERT from scratch with cloud TPU를 기반으로 작성되었습니다.