Selenium WebDriver를 이용해 실제 브라우저를 동작시켜 크롤링을 진행할 때 가끔가다보면 NoSuchElementException라는 에러가 나는 경우를 볼 수 있습니다.
가장 대표적인 사례가 바로 JS를 통해 동적으로 HTML 구조가 변하는 경우인데요, 만약 사이트를 로딩한 직후에(JS처리가 끝나지 않은 상태에서) JS로 그려지는 HTML 엘리먼트를 가져오려고 하는 경우가 대표적인 사례입니다. (즉, 아직 그리지도 않은 요소를 가져오려고 했기 때문에 생기는 문제인 것이죠.)
그래서 크롤링 코드를 작성할 때 크게 두가지 방법으로 브라우저가 HTML Element를 기다리도록 만들어 줄 수 있습니다.
Implicitly wait
Selenium에서 브라우저 자체가 웹 요소들을 기다리도록 만들어주는 옵션이 Implicitly Wait입니다.
# driver를 만든 후 implicitly_wait 값(초단위)을 넣어주세요. driver.implicitly_wait(3)
driver.get('https://www.kakaobank.com/')
# 하나만 찾기 title = driver.find_element_by_css_selector('div.intro_main > h3') # 여러개 찾기 small_titles = driver.find_elements_by_css_selector('div.cont_txt > h3')
print(title.text)
for t in small_titles: print(t.text)
driver.quit()
위 코드를 실행하면 여러분이 .get()으로 지정해준 URL을 가져올 때 각 HTML요소(Element)가 나타날 때 까지 최대 3초까지 ‘관용있게’ 기다려 줍니다.
즉, 여러분이 find_element_by_css_selector와 같은 방식으로 HTML엘리먼트를 찾을 때 만약 요소가 없다면 요소가 없다는 No Such Element와 같은 Exception을 발생시키기 전 모든 시도에서 3초를 기다려 주는 것이죠.
하지만 이런 방식은 만약 여러분이 크롤링하려는 웹이 ajax를 통해 HTML 구조를 동적으로 바꾸고 있다면 과연 ‘3초’가 적절한 값일지에 대해 고민을 하게 만듭니다.(모든 ajax가 진짜로 3초 안에 이루어질까요?)
그래서 우리는 조금 더 발전된 기다리는 방식인 Explicitly wait을 사용하게 됩니다.
NOTE: 기본적으로 Implicitly wait의 값은 0초입니다. 즉, 요소를 찾는 코드를 실행시킨 때 요소가 없다면 전혀 기다리지 않고 Exception을 raise하는 것이죠.
Explicitly wait
자, 여러분이 인터넷 웹 사이트를 크롤링하는데 ajax를 통해 HTML 구조가 변하는 상황이고, 각 요소가 들어오는 시간은 몇 초가 될지는 예상할 수 없다고 가정해 봅시다.
위에서 설정해 준 대로 implicitly_wait을 이용했다면 어떤 특정한 상황(인터넷이 유독 느렸음)으로 인해 느려진 경우 우리가 평소에 기대했던 3초(n초)를 넘어간 경우 Exception이 발생할 것이고 이로 인해 반복적인 크롤링 작업을 진행할 때 문제가 생길 수 있습니다.
따라서 우리는 명확하게 특정 Element가 나타날 때 까지 기다려주는 방식인 Explicitly Wait을 사용할 수 있습니다.
아래 코드는 위에서 Implicitly wait을 통해 사용했던 암묵적 대기(get_element_by_id 등)을 사용한 대신 명시적으로 div.intro_main > h3라는 CSS Selector로 가져오는 부분입니다.
from selenium import webdriver # 아래 코드들을 import 해 줍시다. from selenium.webdriver.common.by import By # WebDriverWait는 Selenium 2.4.0 이후 부터 사용 가능합니다. from selenium.webdriver.support.ui import WebDriverWait # expected_conditions는 Selenium 2.26.0 이후 부터 사용 가능합니다. from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Chrome('chromedriver')
driver.get('https://www.kakaobank.com/')
try: # WebDriverWait와 .until 옵션을 통해 우리가 찾고자 하는 HTML 요소를 # 기다려 줄 수 있습니다. title = WebDriverWait(driver, 10) \ .until(EC.presence_of_element_located((By.CSS_SELECTOR, "div.intro_main > h3"))) print(title.text) finally: driver.quit()
위 코드를 사용하면 우리가 찾으려는 대상을 driver가 명시적으로 ‘10초’를 기다리도록 만들어 줄 수 있습니다.
마치며
만약 여러분이 ajax를 사용하지 않는 웹 사이트에서 단순하게 DOM구조만 변경되는 상황이라면 사실 Explicitly wait을 사용하지 않아도 괜찮을 가능성이 높습니다. (DOM API처리속도는 굉장히 빠릅니다.)
하지만 최신 웹 사이트들은 대부분 ajax요청을 통해 웹 구조를 바꾸는 SPA(Single Page App)이 많기 때문에 크롤링을 진행할 때 Explicitly wait을 이용하는 것이 좋습니다.
DB에 있는 정보를 파이썬 코드 속에서 SQL raw Query를 통해 정보를 가져오는 아래와 같은 코드의 형태는 대다수의 언어에서 지원합니다.
1 2 3 4 5 6 7
import sqlite3
# 굳이 sqlite3이 아닌 다른 MySQL와 같은 DB의 connect를 이뤄도 상관없습니다. # 여기서는 파이썬 파일과 같은 위치에 blog.sqlite3 파일이 있다고 가정합니다. conn = sqlite3.connect("blog.sqlite3") cur = conn.cursor() cur.execute("select * from post where id < 10;")
위와 같은 형식으로 코드를 사용할 경우 웹이 이루어지는 과정 중 2~3번째 과정인 “SQL쿼리 요청하기”와 “데이터 받기”라는 부분을 수동으로 처리해 줘야 하는 부분이 있습니다.
이런 경우 파이썬 파일이더라도 한 파일 안에 두개의 언어를 사용하게 되는 셈입니다. (python와 SQL)
만약 여러분이 Pandas DataFrame객체를 DB에서 가져와 만들려면 이런 문제가 생깁니다.
from datetime import datetime from flask import Flask, jsonify from flask_sqlalchemy import SQLAlchemy import pandas as pd import json
app = Flask(__name__) app.config['SQLALCHEMY_DATABASE_URI'] = 'sqlite:///blog.sqlite3' db = SQLAlchemy(app)
classPost(db.Model): __tablename__ = 'post'
id = db.Column(db.Integer, primary_key=True) title = db.Column(db.String(100)) content = db.Column(db.Text) pub_date = db.Column(db.DateTime, nullable=False, default=datetime.utcnow)
# 아래 줄을 추가해 줍시다. # List post which id is less then 10 @app.route('/') defpost_all(): df = pd.read_sql_query("select * from post where id < 10;", db.session.bind).to_json() return jsonify(json.loads(df))
자, 분명히 ORM을 쓰는데도 아직 SQL 쿼리를 쓰고있네요! SQL쿼리문을 지워버립시다!
queryset 객체를 만들기
우리는 Post라는 모델을 만들어줬으니 이제 Post객체의 .query와 .filter()를 통해 객체들을 가져와 봅시다.
우선 queryset라는 이름에 넣어줍시다. 그리고 Pandas의 read_sql(유의: read_sql_query가 아닙니다.)에 queryset의 내용과 세션을 넘겨줘 DataFrame 객체로 만들어줍시다.
from datetime import datetime from flask import Flask, jsonify from flask_sqlalchemy import SQLAlchemy import pandas as pd import json
app = Flask(__name__) app.config['SQLALCHEMY_DATABASE_URI'] = 'sqlite:///blog.sqlite3' db = SQLAlchemy(app)
classPost(db.Model): __tablename__ = 'post'
id = db.Column(db.Integer, primary_key=True) title = db.Column(db.String(100)) content = db.Column(db.Text) pub_date = db.Column(db.DateTime, nullable=False, default=datetime.utcnow)
# List post which id is less then 10 @app.route('/') defpost_all(): # 이 줄은 지우고, # df = pd.read_sql_query("select * from post where id < 10;", db.session.bind).to_json() # 아래 두줄을 추가해주세요. queryset = Post.query.filter(Post.id < 10) # SQLAlchemy가 만들어준 쿼리, 하지만 .all()이 없어 실행되지는 않음 df = pd.read_sql(queryset.statement, queryset.session.bind) # 진짜로 쿼리가 실행되고 DataFrame이 만들어짐 return jsonify(json.loads(df).to_json())
자, 위와 같이 코드를 짜 주면 이제 SQLAlchemy ORM와 Pandas의 read_sql을 통해 df이 DataFrame 객체로 자연스럽게 가져오게 됩니다.
정리하기
여러분이 Pandas를 사용해 데이터를 분석하거나 정제하려 할 때 웹앱으로 Flask를 사용하고 ORM을 이용한다면, 굳이 SQL Query를 직접 만드는 대신 이처럼 Pandas와 SQLAlchemy의 강력한 조합을 이용해 보세요. 조금 더 효율적인 시스템 활용을 고려한 파이썬 프로그램이 나올거에요!
TL;DR
아래 코드와 같이 모델을 만들고 db 객체를 만든 뒤 pandas의 read_sql을 사용하면 됩니다.
from datetime import datetime from flask import Flask, jsonify from flask_sqlalchemy import SQLAlchemy import pandas as pd import json
app = Flask(__name__) app.config['SQLALCHEMY_DATABASE_URI'] = 'sqlite:///blog.sqlite3' db = SQLAlchemy(app)
classPost(db.Model): __tablename__ = 'post'
id = db.Column(db.Integer, primary_key=True) title = db.Column(db.String(100)) content = db.Column(db.Text) pub_date = db.Column(db.DateTime, nullable=False, default=datetime.utcnow)
# List post which id is less then 10 @app.route('/') defpost_all(): queryset = Post.query.filter(Post.id < 10) # SQLAlchemy가 만들어준 쿼리, 하지만 .all()이 없어 실행되지는 않음 df = pd.read_sql(queryset.statement, queryset.session.bind) # 진짜로 쿼리가 실행되고 DataFrame이 만들어짐 return jsonify(json.loads(df).to_json())
# models.py 파일 # coding: utf-8 from sqlalchemy import Boolean, Column, DateTime, ForeignKey, Index, Integer, String, Table, Text from sqlalchemy.orm import relationship from sqlalchemy.sql.sqltypes import NullType from flask_sqlalchemy import SQLAlchemy
if __name__=='__main__': app = create_app() app.run()
앞서 만들어준 models.py파일을 가져와 create_app 함수를 통해 app을 lazy_loading해주는 과정을 통해 진행해 줄 수 있습니다.
마치며
기존에 사용하던 DB를 Flask와 SqlAlchemy를 통해 ORM으로 이용해 좀 더 빠른 개발이 가능하다는 것은 큰 이점입니다. ORM에서 DB 생성을 하지 않더라도 이미 있는 DB를 ORM으로 관리하고 Flask 프로젝트에 바로 가져다 쓸 수 있다는 점이 좀 더 빠른 프로젝트 진행에 도움이 될거랍니다.
파이썬의 버전 2와 3이 다른 것은 누구나 알고 2017년인 오늘은 대부분 Python3버전을 이용해 프로젝트를 진행합니다. 하지만 자바스크립트에 버전이 있고 새로운 기능이 나온다 하더라도 이 기능을 바로 사용하는 경우는 드뭅니다. 물론 node.js를 이용한다면 자바스크립트의 새로운 버전의 기능을 바로바로 이용해볼 수 있지만 프론트엔드 웹 개발을 할 경우 새로 만들어진 자바스크립트의 기능을 사용하는 것은 상당히 어렵습니다.
1 2 3 4 5 6
// 이런 문법은 사용하지 못합니다. const hello = 'world' const printHelloWorld = (e) => { console.log(e) } printHelloWorld(hello)
가장 큰 차이는 실행 환경의 문제인데요, 우리가 자주 사용하는 크롬브라우저의 경우에는 자동업데이트 기능이 내장되어있어 일반 사용자가 크롬브라우저를 실행만 해도 최신 버전을 이용하지만, 인터넷 익스플로러나 사파리와 같은 경우에는 많은 사용자가 OS에 설치되어있던 버전 그대로를 이용합니다. 물론 이렇게 사용하는 것도 심각한 문제를 가져오지는 않지만, 구형 브라우저들은 새로운 자바스크립트를 이해하지 못하기 때문에 이 브라우저를 사용하는 사용자들은 새로운 자바스크립트로 개발된 웹 사이트를 접속할 경우 전혀 다르게 혹은 완전히 동작하지 않는 페이지를 볼 수 있기 때문에 많은 일반 사용자를 대상으로 하는 서비스의 경우 새 버전의 자바스크립트를 사용해 개발한다는 것이 상당히 모험적인 성향이 강합니다.
글쓴 시점인 2017년 10월 최신 자바스크립트 버전은 ES2017로 ES8이라 불리는 버전입니다. 하지만 이건 정말 최신 버전의 자바스크립트이고, 중요한 변화가 등장한 버전이 2015년도에 발표된 ES2015, 다른 말로는 ES6이라고 불리는 자바스크립트입니다. 하지만 인터넷익스플로러를 포함한 대부분의 브라우저들이 지원하는 자바스크립트의 버전은 ES5로 이보다 한단계 낮은 버전을 사용합니다. 따라서 우리는 ES6혹은 그 이상 버전의 자바스크립트 코드들을 ES5의 아래 버전 자바스크립트로 변환해 사용하는 방법을 사용할 수 있습니다.
Babel
여기서 바로 Babel이 등장합니다. Babel은 최신 자바스크립트를 ES5버전에서도 돌아갈 수 있도록 변환(Transpiling)해줍니다. 우리가 자바스크립트 최신 버전의 멋진 기능을 이용하는 동안, Babel이 다른 브라우저에서도 돌아갈 수 있도록 처리를 모두 해주는 것이죠!
물론, Babel이 마법의 요술도구처럼 모든 최신 기능을 변환해주지는 못합니다. 하지만 아래 사진처럼 다양한 브라우저에 따라 최신 JavaScript문법 중 어떠 부분까지가 실행 가능한 범위인지 알려줍니다.
Webpack
ES6에서 새로 등장한 것 중 유용한 문법이 바로 import .. from ..구문입니다. 다른 언어에서의 import와 유사하게 경로(상대경로 혹은 절대경로)에서 js파일을 불러오는 방식으로 동작합니다.
예를들어 어떤 폴더 안에 Profile.js와 index.js파일이 있다고 생각해 봅시다.
하는일이라고는 name, email을 받는 것, 그리고 hello하는 함수밖에 없지만 우선 Profile이라는 class를 하나 만들었습니다.
여기서 Profile 클래스 앞에 export를 해 주었는데, export를 해 줘야 다른 파일에서 import가 가능합니다.
자, 아래와 같이 index.js파일을 하나 만들어 봅시다.
1 2 3 4 5
// index.js import { Profile } from'./Profile'
const pf = new Profile('Beomi', 'jun@beomi.net') console.log(pf.hello())
이 파일은 현재 경로의 Profile.js파일 중 Profile 클래스를 import해와 새로운 인스턴스를 만들어 사용합니다.
하지만 안타깝게도 이 index.js파일은 실행되지 않습니다. 아직 webpack으로 처리를 해주지 않았기 때문이죠!
webpack-dev-server
webpack은 파일을 모아 하나의 js파일로 만들어줍니다.(보통 bundle.js라는 이름을 많이 씁니다.) 하지만 실제 개발중 js파일을 수정할 때마다 Webpack을 실행해 번들작업을 해준다면 시간도 많이 걸리고 매우 귀찮습니다. 이를 보완해 주는 패키지가 바로 webpack-dev-server 인데요, 이 패키지를 사용하면 여러분이 실제 빌드를 해 bundle.js파일을 만들지 않아도 메모리 상에 가상의 bundle.js파일을 만들어 여러분이 웹 사이트를 띄울때 자동으로 번들된 js파일을 띄워줍니다. 그리고 소스가 수정될 때 마다 업데이트된(번들링된) bundle.js파일로 띄워주고 화면도 새로고침해줍니다!
NOTE: webpack-dev-server는 build를 자동으로 해주는 것은 아닙니다. 단지 미리 지정해둔 경로로 접근할 경우 (실제로는 파일이 없지만) bundle.js파일이 있는 것처럼 파일을 보내주는 역할을 맡습니다. 개발이 끝나고 실제 서버에 배포할때는 이 패키지 대신 실제 webpack을 통해 빌드 작업을 거친 최종 결과물을 서버에 올려야 합니다.
설치하기
우선 npm프로젝트를 생성해야 합니다. index.js파일을 만든 곳(어떤 폴더) 안에서 다음 명령어로 “이 폴더는 npm프로젝트를 이용하는 프로젝트다” 라는걸 알려주세요.
babel-loader는 webpack이 .js 파일들에 대해 babel을 실행하도록 만들어주고, babel-core는 babel이 실제 동작하는 코드이고, babel-preset-env는 babel이 동작할 때 지원범위가 어느정도까지 되어야 하는지에 대해 지정하도록 만들어주는 패키지입니다.
이렇게 설치를 진행하고 나면 Babel과 Webpack을 사용할 준비를 마친셈입니다.
NOTE: package.json뿐 아니라 package-lock.json파일도 함께 생길수 있습니다. 이 파일은 npm패키지들이 각각 수많은 의존성을 가지고 있기 때문에 의존성 패키지들을 다운받는 URL을 미리 모아둬 다른 컴퓨터에서 package.json을 통해 npm install로 패키지들을 설치시 훨씬 빠른 속도로 패키지를 받을 수 있도록 도와줍니다.
이제 설정파일 몇개를 만들고 수정해줘야 해요.
설정파일 건드리기
package.json
package.json파일은 파이썬 pip의 requirements.txt처럼 패키지버전 관리만 해주는 것이 아니라 npm와 결합해 특정 명령어를 실행하거나 npm 프로젝트의 환경을 담는 파일입니다.
위 파일은 entry에 현재 위치의 index.js파일을 들어가 모든 import를 찾아오고, module -> rules -> include에 있는 .js로 된 모든 파일을 babel로 처리해줍니다.(exclue에 있는 부분인 node_modules폴더와 dist폴더는 제외합니다.)
index.html
사실 우리는 아직 번들링된 js파일을 보여줄 HTML파일이 없습니다! 우선 bundle.js를 보여주기만 할 단순한 HTML파일을 하나 만들어 봅시다.(index.js와 같은 위치)
이번 글은 Ubuntu16.04 LTS / Python3 / Apache2.4 서버 환경으로 진행합니다.
들어가며
플라스크를 서버에 배포하는 것은 장고 배포와는 약간 다릅니다. 기본적으로 Apache2를 사용하기 때문에 mod_wsgi를 사용하는 것은 동일하지만, 그 외 다른 점이 조금 있습니다.
우선 간단한 플라스크 앱 하나가 있다고 생각을 해봅시다. 가장 단순한 형태는 아래와 같이 루트로 접속시 Hello world!를 보여주는 것이죠.
1 2 3 4 5 6 7 8
# app.py from flask import Flask
app = Flask(__file__)
@app.route('/') defhello(): return"Hello world!"
물론 여러분이 실제로 만들고 썼을 프로젝트는 이것보다 훨씬 복잡하겠지만, 일단은 이걸로 시작은 할 수 있답니다.
wsgi.py 파일 만들기
로컬에서 app.run() 을 통해 실행했던 테스트서버와는 달리 실 배포 상황에서는 Apache나 NginX와 같은 웹서버를 거쳐 웹을 구동하고, 따라서 app.run()의 방식은 더이상 사용할 수 없습니다. 대신 여러가지 웹서버와 Flask를 연결시켜주는 방법이 있는데, 이번엔 그 중 wsgi를 통해 Apache서버가 Flask 앱을 실행하도록 만들어줄 것이랍니다.
우선 wsgi.py파일을 하나 만들어야 합니다. 이 파일은 나중에 Apache서버가 이 파일을 실행시켜 Flask서버를 구동하게 됩니다. 그리고 이 파일은 위에서 만든 변수인 app = Flask(__file__), 즉 app변수를 import할 수 있는 위치에 있어야 합니다. (app.py파일과 동일한 위치에 두면 무방합니다.)
우리가 wsgi를 통해 실행할 경우 프로그램은 application이라는 변수를 찾아 run()와 비슷한 명령을 실행해 서버를 구동합니다. 따라서 우리는 wsgi.py파일 내 application이라는 변수를 만들어줘야 하는데, 이 변수는 바로 app.py내의 app변수입니다.
위 코드를 보시면 sys모듈과 os모듈을 사용합니다. os모듈의 getcwd()함수를 통해 현재 파일의 위치를 시스템의 PATH 경로에 넣어줍니다. 이 줄을 통해 바로 아래에 있는 from app import app이라는 구문에서 from app 부분이 현재 wsgi.py파일의 경로에서 app.py를 import할 수 있게 되는 것이죠. 만약 이 줄이 빠져있다면 ImportError가 발생하며 app이라는 모듈을 찾을 수 없다는 익셉션이 발생합니다.
Fabric3 설치하기
Fabric3은 Python2만 지원하던 fabric프로젝트를 포크해 Python3을 지원하도록 업데이트한 패키지입니다. 우선 pip로 패키지를 설치해 줍시다.
이제 우리는 fab이라는 명령어를 사용할 수 있습니다. 이 명령어를 통해 fabfile.py 파일 내의 함수를 실행할 수 있게 됩니다.
fabfile.py 파일 만들기
Fabric은 그 자체로는 하는 일이 없습니다. 사실 fabric은 우리가 서버에 들어가서 ‘Git으로 소스를 받고’, ‘DB를 업데이트하고’, ‘Static파일을 정리하며’, ‘웹서버 설정을 업데이트’해주는 일들을 하나의 마치 배치파일처럼 자동으로 실행할 수 있도록 도와주는 도구입니다.
하지만 이 도구를 사용하려면 우선 fabfile.py라는 파일이 있어야 fabric이 이 파일을 읽고 파일 속의 함수를 실행할 수 있게 됩니다.
fabfile을 만들기 전 deploy.json이라는 이름의 json파일을 만들어 아래와 같이 설정을 담아줍시다.
우선 REPO_URL을 적어줍시다. 이 REPO에서 소스코드를 받아 처리해줄 예정이기 때문이죠. 그리고 PROJECT_NAME을 설정해 주세요. 일반적인 상황이라면 REPO의 이름과 같에 넣어주면 됩니다. 그리고 REMOTE_HOST는 서버의 주소가 됩니다. http등을 제외한 ‘도메인’부분만 넣어주세요. 그리고 서버에 SSH로 접속할 수 있는 IP를 REMOTE_HOST_SSH에 넣어주고, 마지막으로 sudo권한을 가진 유저이름을 REMOTE_USER에 넣어주세요.
# put이라는 방식으로 로컬의 파일을 원격지로 업로드할 수 있습니다. def_put_envs(): pass# activate for envs.json file # put('envs.json', '~/{}/envs.json'.format(PROJECT_NAME))
# apt 패키지를 업데이트 할 지 결정합니다. def_get_latest_apt(): update_or_not = input('would you update?: [y/n]') if update_or_not == 'y': sudo('apt-get update && apt-get -y upgrade')
# 필요한 apt 패키지를 설치합니다. def_install_apt_requirements(apt_requirements): reqs = '' for req in apt_requirements: reqs += (' ' + req) sudo('apt-get -y install {}'.format(reqs))
# Apache2의 Virtualhost를 설정해 줍니다. # 이 부분에서 wsgi.py와의 통신, 그리고 virtualenv 내의 파이썬 경로를 지정해 줍니다. def_make_virtualhost(): script = """'<VirtualHost *:80> ServerName {servername} <Directory /home/{username}/{project_name}> <Files wsgi.py> Require all granted </Files> </Directory> WSGIDaemonProcess {project_name} python-home=/home/{username}/.virtualenvs/{project_name} python-path=/home/{username}/{project_name} WSGIProcessGroup {project_name} WSGIScriptAlias / /home/{username}/{project_name}/wsgi.py {% raw %} ErrorLog ${{APACHE_LOG_DIR}}/error.log CustomLog ${{APACHE_LOG_DIR}}/access.log combined {% endraw %} </VirtualHost>'""".format( username=REMOTE_USER, project_name=PROJECT_NAME, servername=REMOTE_HOST, ) sudo('echo {} > /etc/apache2/sites-available/{}.conf'.format(script, PROJECT_NAME)) sudo('a2ensite {}.conf'.format(PROJECT_NAME))
# Apache2가 프로젝트 파일을 읽을 수 있도록 권한을 부여합니다. def_grant_apache2(): sudo('chown -R :www-data ~/{}'.format(PROJECT_NAME)) sudo('chmod -R 775 ~/{}'.format(PROJECT_NAME))
# 마지막으로 Apache2를 재시작합니다. def_restart_apache2(): sudo('sudo service apache2 restart')
위 코드를 fabfile.py에 넣어주고 나서
첫 실행시에는 fab new_server
코드를 수정하고 push한 뒤 서버에 배포시에는 fab deploy
명령을 실행해 주면 됩니다.
NOTE: _ 로 시작하는 함수는 fab 함수이름으로 실행하지 못합니다.
자, 이제 서버에 올릴 준비가 되었습니다.
서버에 올리기
우분투 서버를 만들고 첫 배포라면 new_server를, 한번 new_server를 했다면 deploy로 배포를 진행합니다.
fabfile내의 apt_requirements 리스트에는 프로젝트마다 필요한 다른 패키지들을 적어줘야 합니다.
만약 여러분의 프로젝트에서 mysqlclient패키지등을 사용한다면 libmysqlclient-dev를 apt_requirements리스트에 추가해줘야 합니다. 혹은 PostgreSQL을 사용한다면 libpq-dev가 필요할 수도 있습니다. 그리고 여러분이 이미지 처리를 하는 pillow패키지를 사용한다면 libjpeg62-dev를 apt_requirements에 추가해야 할 수도 있습니다.
이처럼 여러분이 파이썬 패키지에서 어떤 상황이냐에 따라 다른 apt패키지 리스트를 넣어줘야 합니다.
번역을 할 때 대상이 이미 doc파일같은 것이라면 사실 이 부분은 걱정하지 않아도 괜찮습니다. 하지만 만약 여러분이 책 번역등 의뢰를 받아 진행한다면 PDF로 책을 받을 가능성이 꽤 높습니다. 물론 PDF를 켜놓고 word창을 하나 옆으로 두 창을 띄워두며 한글로 번역해도 일이 가능하기는 합니다. 하지만 최근 React문서를 번역하며 사용했던 도구인 crowdin이나 Django문서 번역할때 사용하는 transifex를 떠올려보면 이게 무슨 삽질인가, 하는 생각이 듭니다.
그래서 여러분이 번역을 하기 위해 crowdin이나 transifex를 사용하려 사이트에 들어가보면,
월 단위 pricing인 것을 넘어 가격대가 상당히 높게 형성되어있는 것을 볼 수 있습니다. (ㅠㅠ) 저 두 서비스는 분명히 멋지고 좋은 서비스이지만 매달 가격을 지불하기에는 애매한 측면이 있어 다른 방법을 찾아보았습니다.
우리가 방금 만들어준 ‘cropped_어쩌구.pdf’파일들을 업로드 해 주면 됩니다. 여러개 파일을 한번에 올릴 수 있어 편리합니다 ;)
업로드가 끝나고 변환작업이 완료되면 아래와 같이 Download All버튼이 활성화됩니다.
버튼을 누르면 pdf2docx.zip파일이 받아지고, 이 압축 파일을 풀어주면 다음과 같이 .docx파일로 변환된 파일들이 잘 들어오는 것을 확인할 수 있습니다.
하지만 잘 보시면 크기가 1MB를 넘는 파일이 보입니다. 저 파일들은 구글 번역가 도구에 올릴수 없습니다. 보통 문서가 1MB를 넘는 경우는 이미지의 크기가 큰 것이기 때문에, 이미지의 ppi를 조절해 파일 크기를 줄일 수 있습니다.
.docx파일 크기 줄이기(이미지 ppi줄이기)
1MB가 넘는 한 문서를 열어보니 이미지가 많아 보입니다. 하지만 이미지를 지우면 번역할때 어떤 내용을 다루는지 알아보기 어렵기 때문에 이미지의 해상도(ppi)만 낮춰주도록 하겠습니다.
우선 아래 스샷처럼 아무 이미지나 클릭해주고 나서 화면 위에 뜨는 ‘그림 서식’을 눌러주신 뒤, 핑크색으로 네모 표시 된 버튼을 눌러주세요.
그러면 ‘그림압축’ 메뉴가 뜨고 아래와 같이 그림 품질을 고를 수 있습니다.
최저 ppi인 96ppi로 맞춰주고 ‘잘려진 그림 영역 삭제’에 체크를 눌러주고 ‘이 파일의 모든 그림’으로 맞춰준 후 확인을 눌러주세요. 그리고 저장을 해주시면, 아래와 같이 파일 사이즈가 줄어든 것을 볼 수 있습니다. (기존 1.5MB -> 현재 1MB 조금 덜 됨)
이번 가이드는 가이드 3편(Selenium으로 무적 크롤러 만들기)의 확장편입니다. 아직 selenium을 이용해보지 않은 분이라면 먼저 저 가이드를 보고 오시는걸 추천합니다.
HeadLess Chrome? 머리없는 크롬?
HeadLess란?
Headless라는 용어는 ‘창이 없는’과 같다고 이해하시면 됩니다. 여러분이 브라우저(크롬 등)을 이용해 인터넷을 브라우징 할 때 기본적으로 창이 뜨고 HTML파일을 불러오고, CSS파일을 불러와 어떤 내용을 화면에 그러야 할지 계산을 하는 작업을 브라우저가 자동으로 진행해줍니다.
하지만 이와같은 방식을 사용할 경우 사용하는 운영체제에 따라 크롬이 실행이 될 수도, 실행이 되지 않을 수도 있습니다. 예를들어 우분투 서버와 같은 OS에서는 ‘화면’ 자체가 존재하지 않기 때문에 일반적인 방식으로는 크롬을 사용할 수 없습니다. 이를 해결해 주는 방식이 바로 Headless 모드입니다. 브라우저 창을 실제로 운영체제의 ‘창’으로 띄우지 않고 대신 화면을 그려주는 작업(렌더링)을 가상으로 진행해주는 방법으로 실제 브라우저와 동일하게 동작하지만 창은 뜨지 않는 방식으로 동작할 수 있습니다.
그러면 왜 크롬?
일전 가이드에서 PhantomJS(팬텀)라는 브라우저를 이용하는 방법에 대해 다룬적이 있습니다. 팬텀은 브라우저와 유사하게 동작하고 Javascript를 동작시켜주지만 성능상의 문제점과 크롬과 완전히 동일하게 동작하지는 않는다는 문제점이 있습니다. 우리가 크롤러를 만드는 상황이 대부분 크롬에서 진행하고, 크롬의 결과물 그대로 가져오기 위해서는 브라우저도 크롬을 사용하는 것이 좋습니다.
하지만 여전히 팬텀이 가지는 장점이 있습니다. WebDriver Binary만으로 추가적인 설치 없이 환경을 만들 수 있다는 장점이 있습니다.
윈도우 기준 크롬 59, 맥/리눅스 기준 크롬 60버전부터 크롬에 Headless Mode가 정식으로 추가되어서 만약 여러분의 브라우저가 최신이라면 크롬의 Headless모드를 쉽게 이용할 수 있습니다.
위 코드를 보시면 ChromeOptions()를 만들어 add_argument를 통해 Headless모드인 것과, 크롬 창의 크기, 그리고 gpu(그래픽카드 가속)를 사용하지 않는 옵션을 넣어준 것을 볼 수 있습니다.
제일 중요한 부분은 바로 options.add_argument('headless')라는 부분입니다. 크롬이 Headless모드로 동작하도록 만들어주는 키워드에요. 그리고 크롬 창의 크기를 직접 지정해 준 이유는, 여러분이 일반적으로 노트북이나 데스크탑에서 사용하는 모니터의 해상도가 1920x1080이기 때문입니다. 즉, 여러분이 일상적으로 보는 것 그대로 크롬이 동작할거라는 기대를 해볼수 있습니다!
마지막으로는 disable-gpu인데요, 만약 위 코드를 실행했을때 GPU에러~가 난다면 --disable-gpu로 앞에 dash(-)를 두개 더 붙여보세요. 이 버그는 크롬 자체에 있는 문제점입니다. 브라우저들은 CPU의 부담을 줄이고 좀더 빠른 화면 렌더링을 위해 GPU를 통해 그래픽 가속을 사용하는데, 이 부분이 크롬에서 버그를 일으키는 현상을 보이고 있습니다. (윈도우 크롬 61버전까지는 아직 업데이트 되지 않았습니다. 맥 61버전에는 해결된 이슈입니다.)
그리고 driver 변수를 만들 때 단순하게 chromedriver의 위치만 적어주는 것이 아니라 chrome_options라는 이름의 인자를 함께 넘겨줘야 합니다.
이 chrome_options는 Chrome을 이용할때만 사용하는 인자인데요, 이 인자값을 통해 headless등의 추가적인 인자를 넘겨준답니다.
자, 이제 그러면 한번 실행해 보세요. 크롬 창이 뜨지 않았는데도 naver_main_headless.png파일이 생겼다면 여러분 컴퓨터에서 크롬이 Headless모드로 성공적으로 실행된 것이랍니다!
Headless브라우저임을 숨기기
Headless모드는 CLI기반의 서버 OS에서도 Selenium을 통한 크롤링/테스트를 가능하게 만드는 멋진 모드지만, 어떤 서버들에서는 이런 Headless모드를 감지하는 여러가지 방법을 쓸 수 있습니다.
아래 글에서는 Headless모드를 탐지하는 방법과 탐지를 ‘막는’방법을 다룹니다.(창과 방패, 또 새로운 창!)
# UserAgent값을 바꿔줍시다! options.add_argument("user-agent=Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36")
// overwrite the `languages` property to use a custom getter Object.defineProperty(navigator, 'languages', { get: function() { return ['ko-KR', 'ko']; }, });
// overwrite the `plugins` property to use a custom getter Object.defineProperty(navigator, 'plugins', { get: function() { return [1, 2, 3, 4, 5]; } });
const getParameter = WebGLRenderingContext.getParameter; WebGLRenderingContext.prototype.getParameter = function(parameter) { // UNMASKED_VENDOR_WEBGL if (parameter === 37445) { return'Intel Open Source Technology Center'; } // UNMASKED_RENDERER_WEBGL if (parameter === 37446) { return'Mesa DRI Intel(R) Ivybridge Mobile '; }
return getParameter(parameter); };
['height', 'width'].forEach(property => { // store the existing descriptor const imageDescriptor = Object.getOwnPropertyDescriptor(HTMLImageElement.prototype, property);
// redefine the property with a patched descriptor Object.defineProperty(HTMLImageElement.prototype, property, { ...imageDescriptor, get: function() { // return an arbitrary non-zero dimension if the image failed to load if (this.complete && this.naturalHeight == 0) { return20; } // otherwise, return the actual dimension return imageDescriptor.get.apply(this); }, }); });
// store the existing descriptor const elementDescriptor = Object.getOwnPropertyDescriptor(HTMLElement.prototype, 'offsetHeight');
// redefine the property with a patched descriptor Object.defineProperty(HTMLDivElement.prototype, 'offsetHeight', { ...elementDescriptor, get: function() { if (this.id === 'modernizr') { return1; } return elementDescriptor.get.apply(this); }, });
# inject.py from bs4 import BeautifulSoup from mitmproxy import ctx
# load in the javascript to inject with open('content.js', 'r') as f: content_js = f.read()
defresponse(flow): # only process 200 responses of html content if flow.response.headers['Content-Type'] != 'text/html': return ifnot flow.response.status_code == 200: return
# inject the script tag html = BeautifulSoup(flow.response.text, 'lxml') container = html.head or html.body if container: script = html.new_tag('script', type='text/javascript') script.string = content_js container.insert(0, script) flow.response.text = str(html)
ctx.log.info('Successfully injected the content.js script.')
하지만 사실 이 코드는 정상적으로 동작하지 않을거에요. 헤드리스모드를 끄면 잘 돌아가지만 헤드리스모드를 켜면 정상적으로 동작하지 않아요. 바로 SSL오류 때문입니다.
크롬에서 SSL을 무시하도록 만들수 있고, 로컬의 HTTP를 신뢰 가능하도록 만들 수도 있지만 아직 크롬 Headless모드에서는 지원하지 않습니다.
정확히는 아직 webdriver에서 지원하지 않습니다.
결론
아직까지는 크롬 Headless모드에서 HTTPS 사이트를 ‘완전히 사람처럼’보이게 한뒤 크롤링 하는 것은 어렵습니다. 하지만 곧 업데이트 될 크롬에서는 익스텐션 사용 기능이 추가될 예정이기 때문에 이 기능이 추가되면 복잡한 과정 없이 JS를 바로 추가해 진짜 일반적인 크롬처럼 동작하도록 만들 수 있으리라 생각합니다.
사실 서버 입장에서 위와 같은 요청을 보내는 경우 처리를 할 수 있는 방법은 JS로 헤드리스 유무를 확인하는 방법이 전부입니다. 즉, 서버 입장에서도 ‘식별’은 가능하지만 이로 인해 유의미한 차단은 하기 어렵습니다. 현재로서는 UserAgent 값만 변경해주어도 대부분의 사이트에서는 자연스럽게 크롤링을 진행할 수 있으리라 생각합니다.
이번 가이드를 따라가기 위해서는 HTTP(80/tcp) 포트가 열려있는 서버와 개인 도메인이 필요합니다.
들어가기 전
django, node.js, react, vue와 같은 웹 개발(Backend & Frontend)을 진행하다보면 모바일 디바이스나 타 디바이스에서 로컬 서버에 접근해야하는 경우가 있습니다.
하지만 보통 개발환경에서는 개발기기가 공인 IP를 갖고 있는것이 아니라 내부 NAT에서 개발이 이루어지고, 웹과 내부 개발기기 사이에는 방화벽이 있습니다. 집에서 개발한다면 공유기가, 회사에서 개발한다면 회사의 라우터 정책 기준이 있습니다.
일반적인 경우 네트워크 정책은 나가는(Outbound) 트래픽은 대부분의 포트가 열려있는 한편 들어오는(Inbound) 트래픽에는 극소수의 포트만 열려있습니다.
만약 로컬 서버에서 일반적으로 HTTP가 사용하는 80/tcp 포트로 서버를 띄어놓았다면 대부분의 경우 이 포트는 막혀있습니다. (개발용 서버인 8000/8080/4000/3000등도 마찬가지입니다. 극소수 빼고는 기본적으로 다 막아둡니다.)
이렇게 포트가 막혀있다면 우리가 로컬에 띄어둔 서버가 아무리 모든 IP에서의 접근을 허용한다고 해도 중간에 있는 라우터에서 막아버리기 때문에 LTE등의 모바일 셀룰러같은 외부에서의 접속은 사실상 불가능합니다.
따라서 이를 해결하기 위해 ngrok와 같은 SSH 터널링을 이용합니다. 하지만 ngrok 서비스 서버는 기본적으로 해외에 있고, 무료 Plan의 경우 분당 connection의 개수를 40개로 제한하고 있습니다. 만약 CSS나 JS, 이미지같은 static파일 요청 하나하나가 각각 connection을 사용한다면, 짧은 시간 내 여러번 새로고침은 수십개의 connection을 만들어버리고 ngrok은 요청을 즉시 차단해버립니다.
물론 keep-alive를 지원하는 클라이언트/서버 설정이 이루어지면 connection은 새로고침을 해도 늘어나지 않습니다. 하지만 모든 클라이언트가 keep-alive를 지원하지는 않습니다.
하지만 유료 플랜이라고 해서 무제한 connection을 지원하지는 않기 때문에 마음놓고 새로고침을 하기는 어렵습니다.
이번 가이드에서는 ngrok같이 로컬 개발 서버(장고의 runserver, webpack의 webpack-dev-server)를 다른 서버에 SSH Proxy를 통해 전달하는 법, 그리고 CloudFlare를 통해 HTTPS서버로 만드는 것까지를 다룹니다.
재료준비
80/tcp가 열린 서버가 있어야 합니다
이번 가이드에서는 80/tcp 포트가 열려있는 서버가 “꼭” 있어야 합니다. 물론 서버에는 공인 IP가 할당되어야 합니다. 그래야 나중에 CloudFlare에서 DNS설정을 해줄 수 있습니다.
만약 집에 이런 서버를 둔다면 포트포워딩을 통해 80/tcp만 열어줘도 됩니다.
한국서버가 가장 좋지만(물리적으로 가까우니까) 일본 VPS도 속도면에서 큰 손해를 보지는 않습니다. (물론 게임서버라면 약간 이야기가 다르지만, 웹 서버용으로는 충분합니다.)
이번엔 ubuntu server os를 세팅하는 방법으로 진행합니다. (ubuntu 14.04, 16.04 모두 가능합니다.)
(HTTPS를 쓰려면) 도메인이 있어야 합니다
개인 도메인이 있어야 CloudFlare라는 DNS서비스에 등록을 하고 HTTPS를 이용할 수 있습니다. 도메인이 없거나 HTTPS를 사용하지 않아도 되는 상황이라면 공인 IP만 있어도 무방합니다.
만들어보기
ubuntu 서버와 도메인이 준비되었다면 이제 시작해봅시다!
서버 세팅하기
서버 세팅은 크게 어렵지 않습니다. ssh로 서버에 접속해 아래 명령어를 그대로 입력해보세요.
위 명령어는 47.156.24.36라는 ip를 가진 서버에 beomi라는 사용자로 ssh접속을 하고, 로컬의 8000번 포트를 원격 서버의 80포트로 연결하는 명령어입니다.
즉, localhost:8000 은 47.156.24.36:80와 같아진거죠!
이제 모바일 디바이스에서도 http://47.156.24.36라고 입력하면 개발 서버에 들어올 수 있어요.
CloudFlare로 SSL 붙이기
만약 서버주소를 외우는게 불편하지 않으시고 & HTTPS가 필요하지 않으시다면, 아래부분은 진행하지 않아도 괜찮습니다.
이 챕터에서는 CloudFlare에 도메인을 연결할 때 제공받을 수 있는 SSL서비스를 통해 HTTP로 서빙되는 우리 서비스를 ‘안전한’ HTTPS로 서빙하도록 도와줍니다.
CloudFlare의 Flex SSL을 사용하면 우리 서버가 HTTPS가 아닌 HTTP로 서빙되더라도 클라우드 플레어에서 HTTPS로 만들어줍니다.
사실 이 기능은 보안을 위해서 있는 서비스라고 보기는 어렵습니다. 물론 브라우저/클라이언트와 CloudFlare 간 통신에서는 좀 더 안전한 통신이 가능하지만, 도메인별로 다른 SSL 인증서를 사용하지 않고 여러 도메인을 그룹핑한 인증서를 사용하고 있는 문제가 있고, 결국 CloudFlare와 우리 서버간에는 HTTP로 통신이 이루어지기 때문에 CloudFlare와 우리 서버 사이 Node에서 이루어지는 공격은 막기 어렵습니다. 따라서 이런 경우는 Geolocation와 같은 HTTPS 위에서만 사용할 수 있는 기능등을 테스트 서버를 통해 구동할 경우 유용합니다.
우선 CloudFlare에 가입하고 도메인을 CloudFlare에 등록해주세요.
도메인을 등록하고 DNS 탭에 들어가서 다음과 같이 서브 도메인(혹은 루트 도메인)을 서버 ip에 연결한 후 우측 하단의 구름모양을 켜 주세요. 이 구름모양을 켜 주면 이 도메인으로 온 요청은 CloudFlare의 CDN망을 통해 전달됩니다. (CSS/JS캐싱도 해줍니다!)
도메인을 등록했으면 아래와 같이 Crypto탭에서 SSL을 Flexible로 바꿔주세요.
off: 말 그대로 HTTPS를 끕니다.
flexible: 우리 서버가 HTTP라도 클라우드플레어로 온 HTTPS요청을 우리서버에 HTTP로 바꿔서 보내줍니다.
full: 우리 서버도 HTTPS가 지원되어야 하지만, 꼭 CA에게 인증된 ‘안전한’ 인증서일 필요는 없습니다. 자체서명 인증서라도 괜찮아요.
full (strict): 우리 서버가 CA에게 인증된 ‘안전한’ 인증서를 통해 HTTPS로 서빙을 해야만 합니다. 자체서명 인증서는 쓸 수 없어요.
이 설정은 off에서 다른 옵션으로 바꿔주면 약간의 시간이 걸리지만 안전한 SSL 인증서를 CloudFlare에서 만들어줍니다.
proxy 명령어에 연결하기
보통 runserver와 같은 개발 서버를 띄우는 명령은 자주 사용하지만 우리가 사용하는 긴 명령어는 한번에 치기도 어렵고 옵션 기억하기도 귀찮은 경우가 많습니다. 쉘에서 지원하는 alias를 통해 아래와 같이 만들어줍시다.
# .zshrc / .bashrc / .bash_profile 와 같이 쉘이 켜질때 실행되는 부분에 넣어주세요
alias proxy="ssh beomi@47.156.24.36 -N -R 80:localhost:8000" # alias proxy="ssh 원격서버유저이름@서버ip -N -R 서버포트:localhost:로컬포트" ```
이와 같이 입력하고 저장한 후 터미널을 다시 켜주면 이제 `proxy`라는 명령어를 치면 로컬 개발 서버가 HTTPS로 세상에 오픈되는 것을 볼 수 있습니다 :)
## 마치며
ngrok는 아주 간편하고 좋은 서비스입니다. 하지만 모바일과 PC 웹을 동시에 테스트 하는 경우 connection개수를 금방 넘어버리고 ngrok를 새로 실행할 때마다 도메인 이름이 바뀌는점이 불편해 위와 같이 Proxy서버를 만들어 개발하는데 사용합니다.
다만 CloudFlare의 CSS/JS캐싱 전략에 의해 변경된 파일이 가져와지지 않는 점은 있는데, 이때는 Apache등의 웹서버에서 제공하는 virtualhost기능과 let's encrypt의 무료 SSL 서비스를 조합해 사용하면 CloudFlare없이도 동일하게 환경을 만들어 줄 수 있습니다. 하지만 웹서버 자체에 대한 이해가 필요하며 SSL을 붙이는 일도 상당히 귀찮기때문에 단순하게 CloudFlare에서 도에인 모드를 아래와 같이 'Development Mode'로 설정해 주면 캐싱 하는 것을 방지할 수 있습니다. 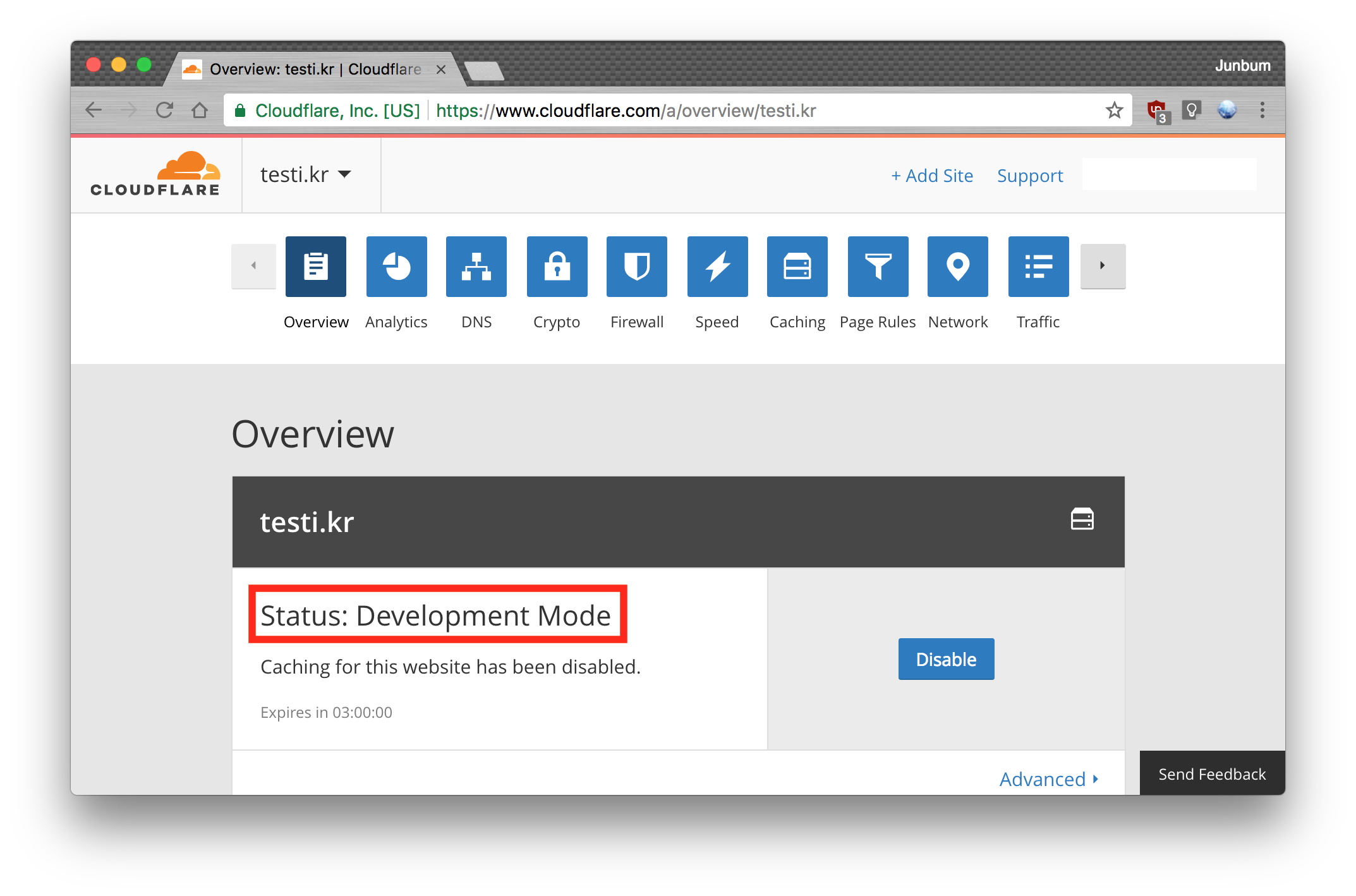 ### 여담 django의 경우에는 `settings.py`파일의 `ALLOWED_HOSTS`에 우리가 지정한 도메인 (ex: shop.testi.kr)을 추가해줘야 합니다. ```python # settings.py ALLOWED_HOSTS = ['*'] # 모든 Host에서의 접근을 허용 # ALLOWED_HOSTS = ['shop.testi.kr'] # shop.testi.kr 도메인 host를 통한 접근을 허용
webpack의 webpack-dev-server에서 위와같이 사용하려면 webpack.config.js파일을 아래와 같이 만들어주면 됩니다.
사실 지금은 코드를 보면 queryset에서 sorted된 값을 반환하고, 이경우에는 쿼리셋 자체가 저 변수로 할당되어버려 다음 request에서 쿼리가 돌지 않는다는 것을 쉽게 찾을 수 있다. 하지만 원래 한번 안보이면 잘 안보이는 법.. 심지어 이 경우에는 Exception이 나는 것도 아니기 때문에 더 찾기 어려웠다.. (ㅠㅠ)
삽질의 시작
여러가지 가정을 할 수 있는 상황이었다.
혹시 브라우저가 리스트를 캐싱하고 있던건 아닐까? (브라우저 캐시)
장고가 View의 Response를 캐싱하고 있는걸까? (장고 캐시)
혹시 DB에 save()가 안된(아예 DB가 업데이트가 되지 않은) 것은 아닐까?
장고 queryset에 캐싱이 되어있었을까?
AJAX call이 비정상적으로 이루어진 것은 아닐까?
아니면, 아예 내 View 로직이 잘못된 것은 아닐까? (CBV인데?)
select_related나 prefetch_related에서 캐싱이 발생하는걸까?
…
이런저런 가정을 하고 하나씩 체크를 해보기로 했다.
아래부분에서는 django 로직과 관련된 삽질만 다뤘습니다. JS쪽은 문제가 없었거든요.
widgets:
첫번째 삽질: “브라우저가 캐싱을 하고 있는건 아닐까?”
만약 브라우저가 HTML파일을 캐싱하고 있다면
캐시 삭제후 강력 새로고침을 하거나,
다른 브라우저로 접근하면
정상적인 화면이 나와야 했다.
그러나… “#망했어요”
브라우저가 캐싱하고 있는게 아니었고, 다른 브라우저에서도 기존(업데이트 전)값을 가져왔다.
widgets:
두번째 삽질: “장고가 template 렌더링 된것을 캐싱하는게 아닐까?”
사실 장고에서 response는 따로 캐싱을 명시적으로 하지 않으면 쿼리가 새로 발생해야 하는 경우에는 캐싱을 하지 않는다.
하지만 일단 template을 재 렌더링 하지 않는게 아닐까… 하는 생각에 아래와 같은 부분을 추가해 보았다.
1 2 3
{% raw %}{% for object in object_list %} {{ object }} 이건 object다 {% endfor %}{% endraw %}
역시 .. “응 아니야~ 장고 일 잘하고 있음”
템플릿은 렌더링이 충분히 잘 되고 있었다.
뭐가 문제일까?
widgets:
세번째 삽질: “.save() 메소드의 사용을 잘못한게 아닐까?”
아예 다음번에는 DB에 저장이 되지 않고 있는게 아닌가.. 하는 생각에 save()와 update()의 사용법을 찾고, force_insert=True와 같은 옵션을 넣어보기도 했다.
1 2 3 4 5 6 7 8 9
# view.py 파일에서... # ... for m_pay in mentor_payment_list: if str(m_pay.pk) in cleaned_keys: m_pay.status = 1 else: m_pay.status = 0 m_pay.save(update_fields=['status']) # ...
.save()는 모델 인스턴스에 적용하는 케이스이고, .update()는 쿼리셋에 적용하는 방법이다. save()의 경우 모델 인스턴스를 가져오기 위해 SELECT 쿼리를 한번 날리고 값을 변경 후 UPDATE를 해주는 방법이라면, update()는 쿼리 자체를 SELECT쿼리로 날리는 방식이다. 따라서 만약의 경우 .update()를 실행 중 다른 요청에서 값이 변경되었다면 그 Transaction이 손실될 수 있고, 모델 인스턴스의 값 자체를 이용해 업데이트하는 방법은 사용하기 어렵다. (물론 사용은 가능하지만 SELECT쿼리같이 .get()으로 한번 가져와야 하기때문에 큰 의미는 없습니다. 여전히 중간에 값이 변경되었을 경우에 기존 값(get)에 대한 불가능하고요.)
m_pay.save(update_fields=['status'])에서는 save()에 update_fields 리스트를 넣어주었다. 일반적인 save()함수가 인스턴스 전체를 변경하는 UPDATE문을 사용하지만 update_fields가 있는 경우에는 force_insert가 자동으로 True가 되며 동시에 해당되는 Column만 update가 일어난다.
사실 DJDT(Django Debug Toolbar)를 사용하며 쿼리의 개수를 확인해보는데 첫 요청시에는 6개의 쿼리가 가는데 비해 두번째 요청부터는 3개의 쿼리만이 실행되고, 그마저도 데이터를 가져오는 쿼리는 없고 세션/로그인등의 비교만 쿼리를 실행하고 있다는 것을 발견해 쿼리셋쪽의 문제라는 것을 알 수 있었다.
여담
문제의 코드 부분(아래)에서 select_related와 prefetch_related를 제거하면 쿼리수는 몇십개로 증가하지만 데이터 자체는 정상적으로 가져왔다. 이건 또 왜그랬을까?
1 2 3 4 5 6 7 8 9
# 문제의 코드.. classOrderMatchingList(ListView): classMeta: model = Order