
우리가 어떤 정보를 브라우저에서만 보는 것 뿐 아니라 그 정보들을 내가 이용하기 편한 방식(ex: json)으로 로컬에 저장하고 싶을 때가 있다.
HTTrack의 경우에는 웹을 그대로 자신의 컴퓨터로 복사를 해오지만, 내가 원하는 방식으로의 가공까지는 제공해주지 않는다.
Python을 이용하면 간단한 코드 몇줄 만으로도 쉽게 웹 사이트에서 원하는 정보만을 가져올 수 있다.
Python에는 requests라는 유명한 http request 라이브러리가 있다.
pip install requests
pip로 간단하게 설치가 가능하다.
Python 파일 하나(ex: parser.py)를 만들어 requests를 import 해준다.
# parser.py
import requests
# HTTP GET Request
req = requests.get('https://beomi.github.io/')
# HTML 소스 가져오기
html = req.text
# HTTP Header 가져오기
header = req.headers
# HTTP Status 가져오기 (200: 정상)
status = req.status_code
# HTTP가 정상적으로 되었는지 (True/False)
is_ok = req.ok
위 코드에서 우리가 사용할 것은 HTML 소스를 이용하는 것이다. 따라서 html=req.text를 이용한다.
Requests는 정말 좋은 라이브러리이지만, html을 ‘의미있는’, 즉 Python이 이해하는 객체 구조로 만들어주지는 못한다. 위에서 req.text는 python의 문자열(str)객체를 반환할 뿐이기 때문에 정보를 추출하기가 어렵다.
따라서 BeautifulSoup을 이용하게 된다. 이 BeautifulSoup은 html 코드를 Python이 이해하는 객체 구조로 변환하는 Parsing을 맡고 있고, 이 라이브러리를 이용해 우리는 제대로 된 ‘의미있는’ 정보를 추출해 낼 수 있다.
pip install bs4
BeautifulSoup을 직접 쳐서 설치하는 것도 가능하지만, bs4라는 wrapper라이브러리를 통해 설치하는 방법이 더 쉽고 안전하다.
위에서 이용한 parser.py파일을 좀 더 다듬어 보자.
# parser.py
import requests
from bs4 import BeautifulSoup
# HTTP GET Request
req = requests.get('https://beomi.github.io/')
# HTML 소스 가져오기
html = req.text
# BeautifulSoup으로 html소스를 python객체로 변환하기
# 첫 인자는 html소스코드, 두 번째 인자는 어떤 parser를 이용할지 명시.
# 이 글에서는 Python 내장 html.parser를 이용했다.
soup = BeautifulSoup(html, 'html.parser')
이제 soup 객체에서 원하는 정보를 찾아낼 수 있다.
BeautifulSoup에서는 여러가지 기능을 제공하는데, 여기서는 select를 이용한다. select는 CSS Selector를 이용해 조건과 일치하는 모든 객체들을 List로 반환해준다.
예시로 이 블로그의 모든 제목을 가져와 보도록 하자.
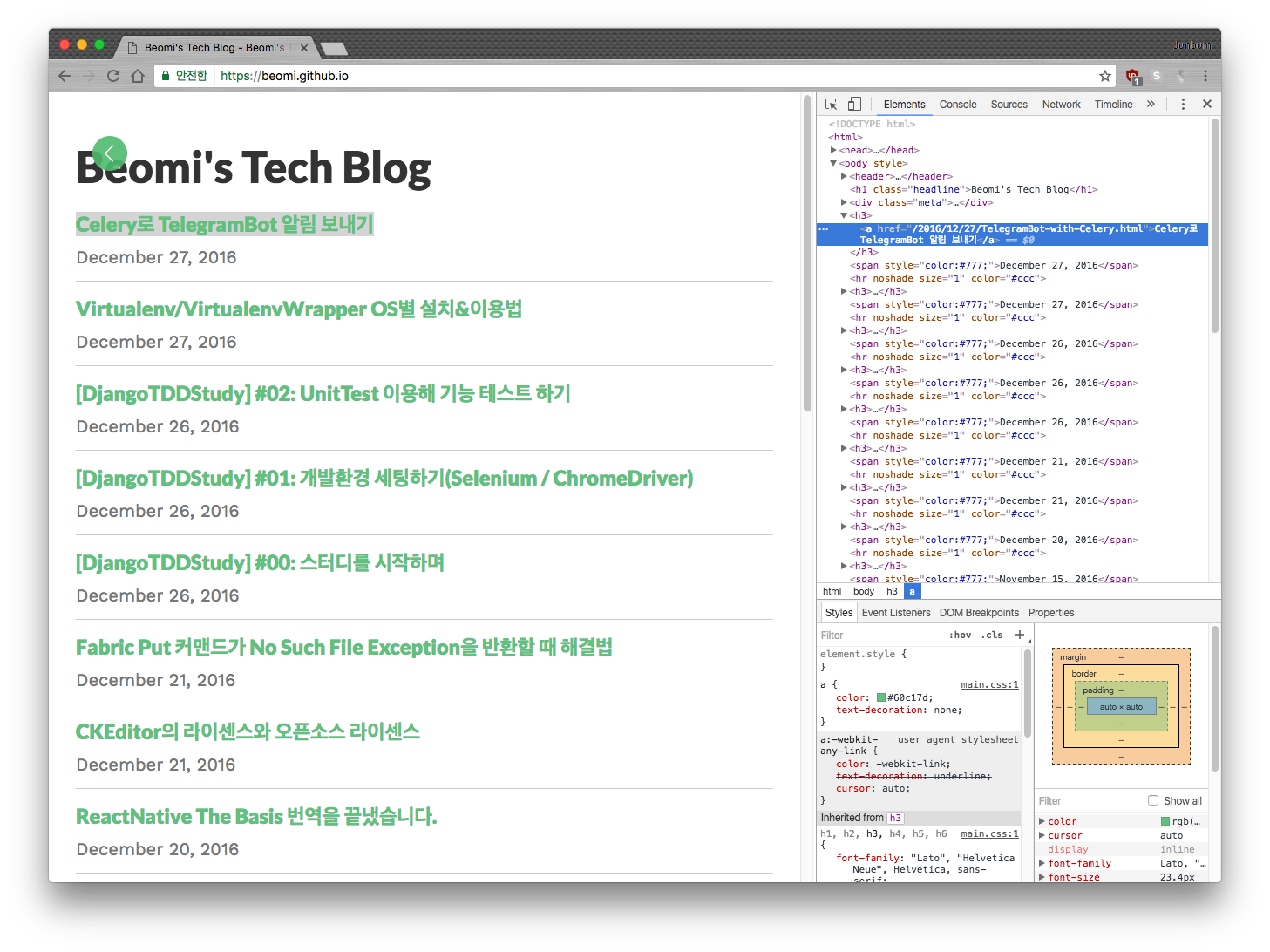
크롬에 내장된 검사도구(요소 위에서 우측 클릭 후 검사)를 이용해보면 현재 title은 a 태그로 구성되어있다는 것을 알 수 있다. 이 상황에서 모든 a 태그를 가져올 수도 있지만, 보다 정확하게 가져오기 위해 CSS Selector를 확인해 보자.
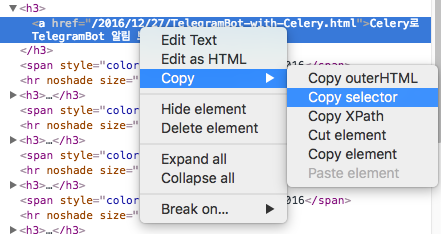
확인해보니 아래와 같은 코드가 나왔다.
body > h3:nth-child(4) > a
하지만 :nth-child(4) 등이 붙어있는 것으로 보아 현재 요소를 ‘정확하게’ 특정하고 있기 때문에, 좀 더 유연하게 만들어 주기 위해 아래와 같이 selector를 바꿔준다.(위 코드는 단 하나의 링크만을 특정하고, 아래 코드는 css selector에 일치하는 모든 요소를 가리킨다.)
h3 > a
이제 parsing.py파일을 더 다듬어 보자.
# parser.py
import requests
from bs4 import BeautifulSoup
req = requests.get('https://beomi.github.io/')
html = req.text
soup = BeautifulSoup(html, 'html.parser')
# CSS Selector를 통해 html요소들을 찾아낸다.
my_titles = soup.select(
'h3 > a'
)
위 코드에서 my_titles는 string의 list가 아니라 soup객체들의 list이다. 따라서 태그의 속성들도 이용할 수 있는데, a 태그의 경우 href속성이 대표적인 예시다.
soup객체는 <태그>로 구성된 요소를 Python이 이해하는 상태로 바꾼 것이라 볼 수 있다. 따라서 여러가지로 조작이 가능하다.
# parser.py
import requests
from bs4 import BeautifulSoup
req = requests.get('https://beomi.github.io/')
html = req.text
soup = BeautifulSoup(html, 'html.parser')
my_titles = soup.select(
'h3 > a'
)
# my_titles는 list 객체
for title in my_titles:
# Tag안의 텍스트
print(title.text)
# Tag의 속성을 가져오기(ex: href속성)
print(title.get('href'))
위와 같이 코드를 처리할 경우 a 태그 안의 텍스트와 a 태그의 href속성의 값을 가져오게 된다. 위 코드에서 title 객체는 python의 dictionary와 같이 태그의 속성들을 저장한다. 따라서 title.get('속성이름')나 title['속성이름']처럼 이용할 수 있다.
select를 통해 요소들을 가져온 이후에는 각자가 생각하는 방식으로 python코드를 이용해 저장하면 된다.
아래 코드는 크롤링한 데이터를 Python파일와 같은 위치에 result.json을 만들어 저장하는 예제다.
# parser.py
import requests
from bs4 import BeautifulSoup
import json
import os
# python파일의 위치
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
req = requests.get('https://beomi.github.io/')
html = req.text
soup = BeautifulSoup(html, 'html.parser')
my_titles = soup.select(
'h3 > a'
)
data = {}
for title in my_titles:
data[title.text] = title.get('href')
with open(os.path.join(BASE_DIR, 'result.json'), 'w+') as json_file:
json.dump(data, json_file)
다음 가이드에서는 Session을 이용해 어떻게 웹 사이트에 로그인을 하고, 로그인 상태를 유지하며 브라우징을 하는지에 대해 알아보겠습니다.