들어가며
BERT와 GPT등 여러 Transformer 기반의 Pretrained model을 통해 보다 쉬운 Transfer learning이 가능하다.
게다가 우리에게는 Huggingface🤗 Transformers 라이브러리를 통해 훨씬 쉽게 downstream task에 여러 모델들을 적용하고/테스트 해 볼 수 있다.
한편, 이와 같은 사전학습된 모델을 적용할 때, 기존 학습된 Corpus의 도메인(ex: 댓글)과 Downstream task에 사용하는 도메인(ex: 금융)이 일치하지 않을 경우 전반적으로 성능이 높지 않게 나오기도 한다.
이뿐만 아니라, 특정 도메인에서 사용하는 Vocab이 Sub-word로 쪼개지는 이슈로 인해 전체적으로 Transformer model에 부하가 가는(학습이 잘 안되는) 상황도 생기게 된다.
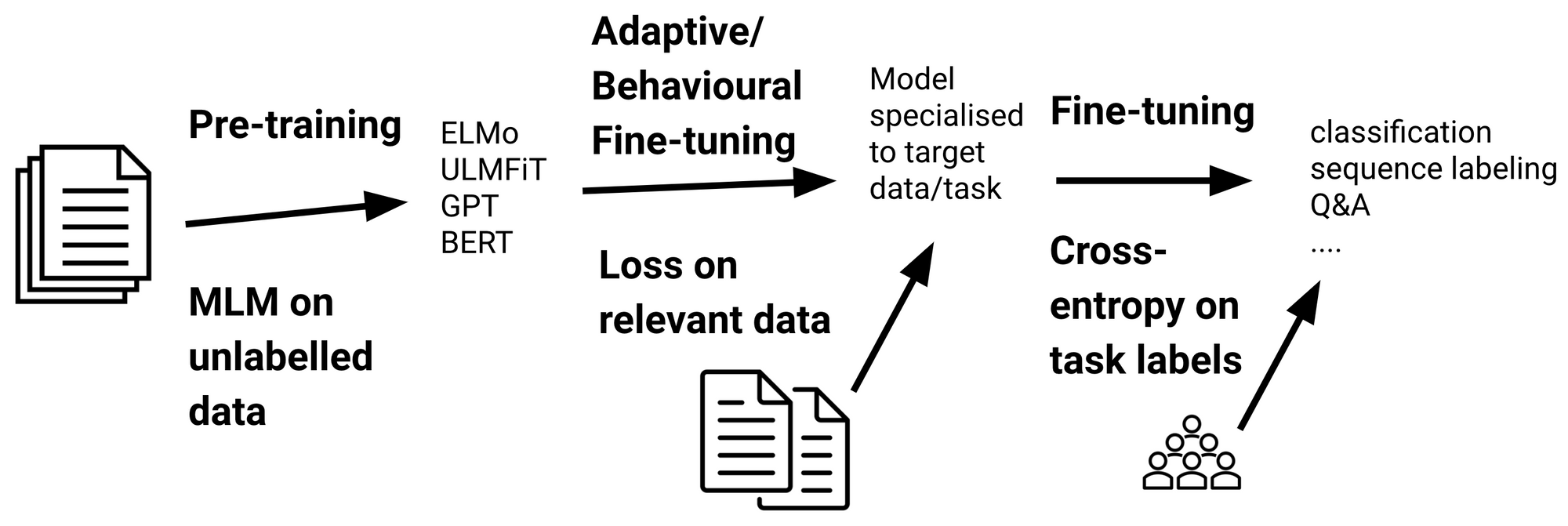
따라서 이번 튜토리얼에서는 Pretrained BERT모델 중 댓글로 학습한 KcBERT를 새로운 도메인 Corpus로 MLM 학습을 추가로 진행해본다.
(용어로는 Domain Adaptive Pretraining이라고 부른다. aka DAPT)
이 튜토리얼은 아래 Github gist와 Colab에서 직접 실행해볼 수 있습니다.
Github Gist: https://gist.github.com/Beomi/972c6442a9c15a22dfd1903d0bb0f577
꼭 DAPT를 해야할까? 처음부터 학습하면 안되나?
사실 최근 컴퓨팅 파워 자체가 무척 많이 올라가면서 BERT-base정도 규모의 학습은(데이터셋 규모와 사용 가능한 컴퓨팅 파워에 따라 다르지만) TPUv3-8 기준 짧게는 1주, 길게는 한달 내외로 학습이 가능하다.
원하는 도메인과 원하는 task에 해당하는 데이터셋이 수십GB만큼 있다면, 오히려 Pretrain from scratch를 하는 것이 더 좋을 수 있다. (Colab에서 TPU로 BERT 처음부터 학습시키기 - Tensorflow/Google ver. 글을 참고해보자.)
하지만 실제로는 관련 도메인의 데이터셋을 GB단위로 구하는 것조차 매우 어렵다. 수집 뿐 아니라 데이터셋에 달린 권리의 문제 등 여러가지 이슈가 따라오기 때문.
따라서 연구를 위해 구할 수 있는 최대한의 규모의 corpus를 제작하되, 기존에 학습된 PLM 모델을 통해 성능을 보다 레버리징 하는 것이 낫다.
(옵션) Vocab을 바꿔서 성능을 높이자
BERT등 Transformer계열의 모델뿐만 아니라 대부분의 embedding이 사용되는 NLP 모델에서 공통적으로 보이는 한계 중 하나가 vocab의 한계, 그리고 주로 [UNK] 로 대표되는 OOV문제다.
이를 해결하기 위해 BPE(CBPE/BBPE) 계열의 Sub-word tokenization이 제안되고 실제로도 높은 성능을 보여주지만, 근본적으로 특정 도메인에서 나타나는 단어들이 수많은 Subword로 쪼개져 Pretrain된 모델에서도 해당 단어의 representation이 제대로 나타나지 않는 현상을 보여준다.
따라서 특정 모델에서는 [unused01] 와 같이 ‘미사용 토큰’을 만들어 downstream task에 finetuning을 진행할 때 해당 부분을 도메인에서 중요한 토큰으로 변환해서 사용할 수도 있다.
이번 과정을 진행할 때 KcBERT 모델에서 사용하는 emoji중 일부를 원하는 도메인의 특정 단어들로 바꾸어 사용해도 성능이 오를 수 있다.
KcBERT PLM MLM Finetune하기
Pretrained KcBERT(base) 모델을 MLM task로 새 데이터셋에 추가적으로 학습을 시켜보자.
필요한 패키지 설치
1 | pip install -q Korpora emoji soynlp kss transformers "datasets >= 1.1.3" "sentencepiece != 0.1.92" protobuf |
- Korpora: 예제 데이터셋 다운받기
- emoji: Unicode emoji 목록 받아오기
- soynlp: KcBERT에서 진행했던 것과 동일하게 데이터 클리닝을 위해 사용
- kss: 예제 데이터셋에서 문단을 문장단위로 분리하기
- transformers: MLM학습을 위해 사용
- datasets, sentencepiece, protobuf는 transformers에서 필요
예시 데이터셋 받고 정제하기
이번 글에서는 Korean petitions dataset(국민청원 데이터셋)을 받아, 본문만 뽑아서 학습을 시켜본다.
국민청원 데이터셋의 전체 크기는 약 43만건이 넘지만, 이 중에서 청원 동의 수가 1000건이 넘은 데이터만 필터링해서 사용해보자. (실제로는 전체를 사용해도 괜찮다.)
1 | from Korpora import Korpora |
위 코드로 데이터셋을 현재 폴더 내 Korpora 폴더에 다운받을 수 있다.
1 | from glob import glob |
실제로 받아진 데이터셋은 jsonl 형식으로, Line-By-Line으로 된 json이다.
pandas로 데이터셋을 읽어 content 컬럼만 뽑아서 사용해보자.
1 | import pandas as pd |

데이터셋을 읽어 pandas dataframe으로 만들면 위와 같이 데이터를 볼 수 있다.
우선 num_agree, 즉 청원 수가 1000 초과인 것만 남겨두자.
1 | agreed_df = df[df['num_agree'] > 1000] |
이 과정을 거치면 데이터셋이 약 3700개로 줄어든다.
그리고 KcBERT에서 사용하는 clean 함수를 그대로 가져오자.
1 | import emoji |
위 함수는 emoji를 살리고, URL을 제거하며, 한글과 영어, 그리고 일반적으로 사용하는 특수문자를 제외하고 모두 공백으로 치환한다.
위 클리닝을 거친 contents 컬럼을 python list로 뽑아내자.
1 | contents = agreed_df['content'].map(clean).to_list() |
KSS로 문장 분리
위에서 추출한 각 본문은 문장별로 쪼개져 있지 않다. 따라서 KSS 라이브러리를 이용해 문장단위로 데이터를 분리해준다.
분리해준 데이터는 korean_petitions_safe.txt 파일에 한 문장씩 써지고, 문서별 \n\n 으로 문서를 분리해줄 수 있다.
1 | from kss import split_sentences |
문서를 분리해주면 BERT의 NSP task를 수행할 수 있다. 문서 분리가 이뤄지지 않으면 사실상 MLM만 학습이 이뤄진다.
이렇게 문장을 분리해줘야 KcBERT의 max_length인 300자 이내로 문장들이 줄여진다.
Huggingface로 MLM 학습하기
Github에서 run_mlm.py 파일을 받아서 학습을 진행해주자.
아래 코드는 beomi/kcbert-base 모델을 받아 vocab 수정 없이 위에서 만든 txt 파일을 기반으로 학습을 진행하는 명령어다.
1 | wget -nc https://raw.githubusercontent.com/huggingface/transformers/4c32f9f26e6a84f0d9843fec8757e6ce640bb44e/examples/language-modeling/run_mlm.py |
실제로 실행시 아래와 같은 로그가 나타나며 Loss값이 잘 떨어지면서 학습이 정상적으로 이루어지는 것을 볼 수 있다.
1 | [...생략...] |
참고: MultiGPU환경에서는 자동으로 DDP로 학습이 이뤄지며, GPU 갯수에 비례하는 batch size로 학습이 이루어진다.
참고: 학습이 완료된 뒤
AttributeError: 'Trainer' object has no attribute 'log_metrics'라는 에러가 발생할 수 있다. 하지만 학습 자체는 정상적으로 이뤄진 것이기에 걱정하지 않아도 된다.
학습 완료된 파일들
학습 과정에는 ./test-mlm/checkpoint-숫자/ 폴더 내에 각 step별 정보가 남는다.
학습이 완료된 이후에는 ./test-mlm/ 폴더 내에 weight파일과 vocab, 그리고 여러 Huggingface 관련 config 파일들이 생긴다.
Checkpoint 폴더를 제외한 나머지를 Huggingface Hub에 업로드해 새로운 모델로 사용할 수 있다.
(참고링크) Huggingface에 모델 업로드하기: https://huggingface.co/transformers/model_sharing.html