
좀 더 보기 편한 깃북 버전의 나만의 웹 크롤러 만들기가 나왔습니다!
@2017.07.12 Update: 뉴클리앙으로 업데이트 됨에 따라 코드와 스크린샷이 업데이트 되었습니다.
웹 사이트를 로그인 하는데 있어 쿠키와 세션을 빼놓고 이야기하는 것은 불가능합니다.
이번 포스팅에서는 requests모듈을 이용해 로그인이 필요한 웹 사이트를 크롤링 하는 예제를 다룹니다.
쿠키(Cookie)? 세션(Session)?
웹은 대다수가 HTTP기반으로 동작합니다. 하지만 HTTP가 구현된 방식에서 웹 서버와 클라이언트는 지속적으로 연결을 유지한 상태가 아니라 요청(request)-응답(response)의 반복일 뿐이기 때문에, 이전 요청과 새로운 요청이 같은 사용자(같은 브라우저)에서 이루어졌는지를 확인하는 방법이 필요합니다. 이 때 등장하는 것이 ‘쿠키’와 ‘세션’입니다.
쿠키는 유저가 웹 사이트를 방문할 때 사용자의 브라우저에 심겨지는 작은 파일인데, Key - Value 형식으로 로컬 브라우저에 저장됩니다. 서버는 이 쿠키의 정보를 읽어 HTTP 요청에 대해 브라우저를 식별합니다.
그러나, 쿠키는 로컬에 저장된다는 근원적인 문제로 인해 악의적 사용자가 쿠키를 변조하거나 탈취해 정상적이지 않은 쿠키로 서버에 요청을 보낼 수 있습니다. 만약 ‘로그인 하였음’이라는 식별을, 로컬 쿠키만을 신뢰해 로그인을 한 상태로 서버가 인식한다면 쿠키 변조를 통해 마치 관리자나 다른 유저처럼 행동할 수도 있는 것이죠.(굉장히 위험합니다.)
이로 인해 서버측에서 클라이언트를 식별하는 ‘세션’을 주로 이용하게 됩니다.
세션은 브라우저가 웹 서버에 요청을 한 경우 서버 내에 해당 세션 정보를 파일이나 DB에 저장하고 클라이언트의 브라우저에 session-id라는 임의의 긴 문자열을 줍니다. 이때 사용되는 쿠키는 클라이언트와 서버간 연결이 끊어진 경우 삭제되는 메모리 쿠키를 이용합니다.
Requests의 Session
이전 게시글에서 다룬 requests모듈에는 Session이라는 도구가 있습니다.
1 | import requests |
Session은 위와 같은 방식으로 만들 수 있습니다.
이렇게 만들어진 세션은 이전 게시글에서의 requests위치를 대신하는데, 이전 게시글의 코드를 바꿔본다면 아래와 같습니다.
1 | # parser.py |
코드를 with구문을 사용해 좀 더 정리하면 아래와 같습니다. 위 코드와 아래코드는 정확히 동일하게 동작하지만, 위쪽 코드의 경우 Session이 가끔 풀리는 경우가 있어 (5번중 한번 꼴) 아래 코드로 진행하는 것을 추천합니다.
1 | # parser.py |
로그인하기
로그인을 구현하기 위한 예시로 클리앙에 로그인 해 클리앙 장터를 크롤링 해 봅시다.
크롬 개발자 도구 중 Inspect(검사)를 이용해 로그인 폼 필드의 name값들을 알아봅시다.(폼 위에서 마우스 오른쪽 버튼을 클릭하고 검사를 눌러주세요.)

아래 스크린샷 우측을 확인해 봅시다. form 태그 안에 input필드가 여러개가 있는 것을 알 수 있습니다.
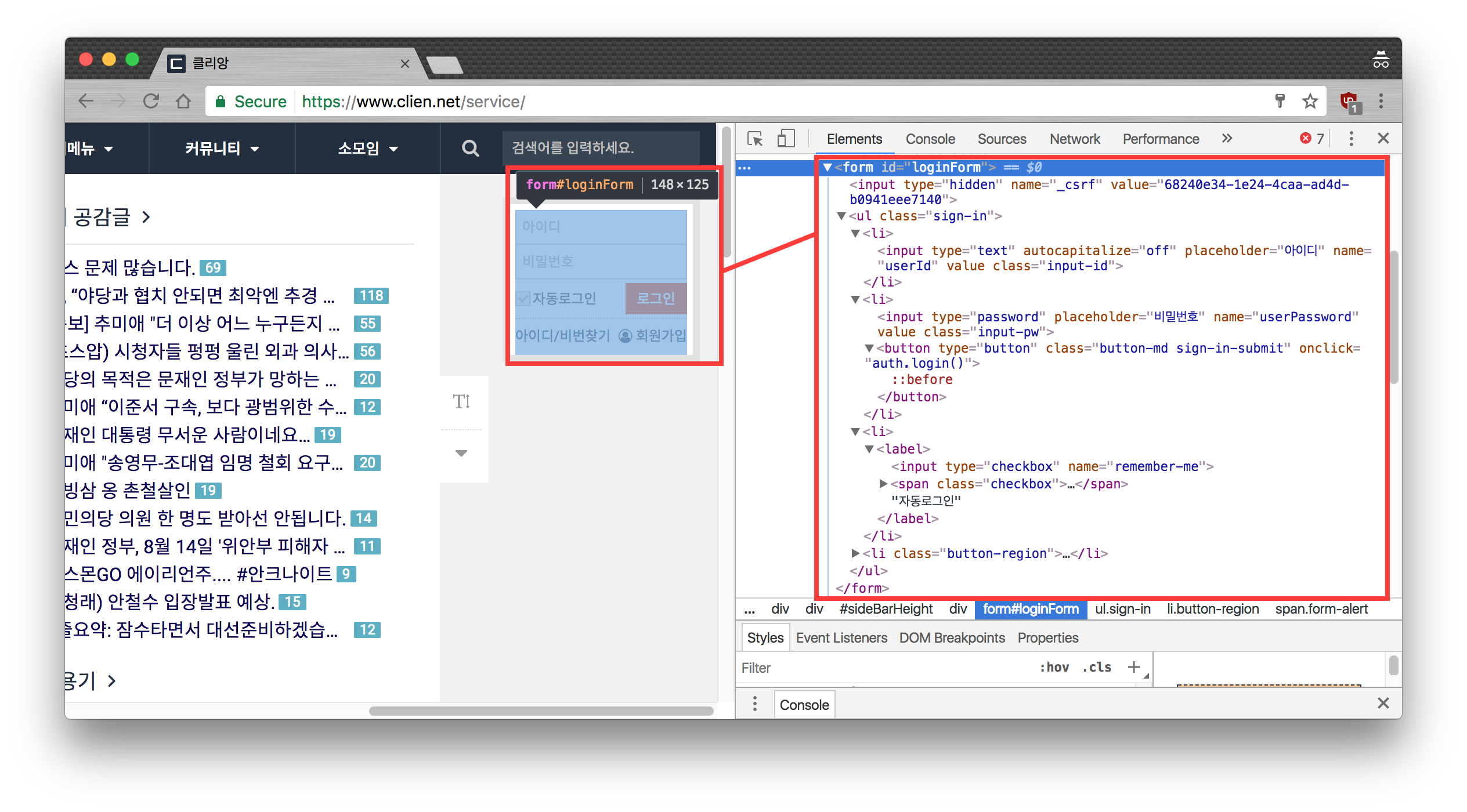
조금 더 상세하게 뜯어봅시다. 아래 스크린샷을 보시면 input필드들의 name이 _csrf,userID,userPassword,remember-me가 있는 것을 볼 수 있습니다. 또한, 로그인 버튼을 누르면 auth.login()라는 자바스크립트 함수가 먼저 실행되는 것을 볼 수 있습니다.
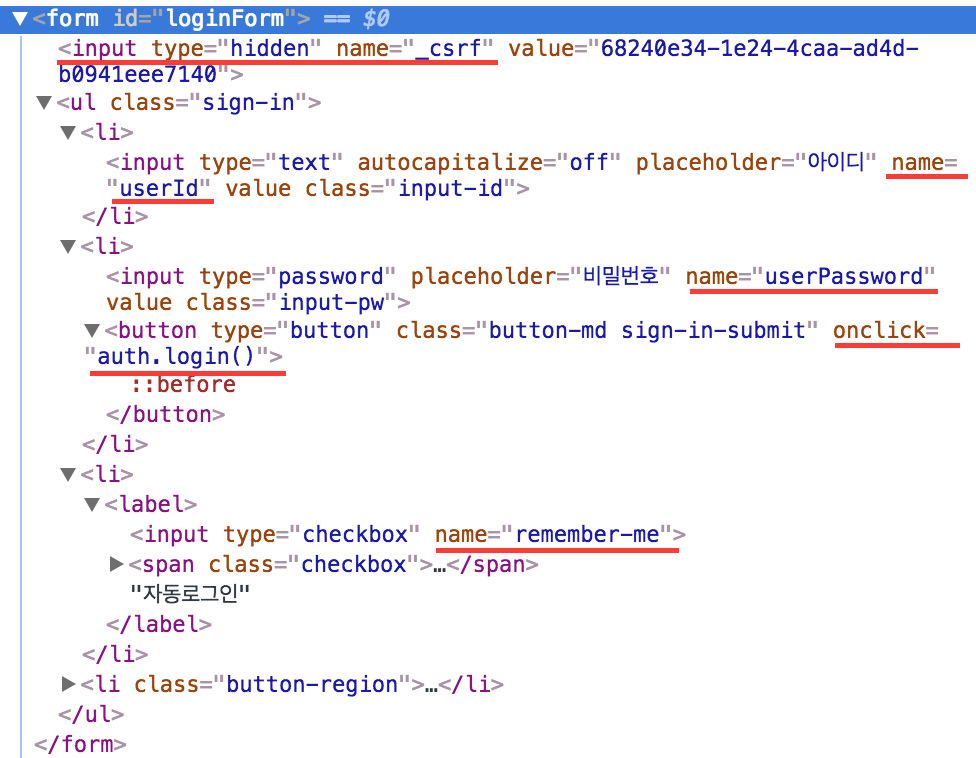
로그인을 구현하기 전, HTML form에 대해 간단하게 알아봅시다.
HTML form Field에서는 name:입력값이라는 Key:Value식으로 데이터를 전달합니다.(주로 POST방식)
클리앙 로그인 폼 필드의 경우 userID:사용자id, userPassword:사용자pw라는 세트로 입력을 받는 것을 볼 수 있습니다.
그리고 약간 특이해 보이는 _csrf이라는 것도 있습니다. 원래 CSRF는 사용자의 요청이 악의적이거나 제 3자에 의해 변조된(해킹된) 요청이 아닌지 확인해주는 보안 도구중 하나입니다. 세션과 연결되어 폼을 전달할때 폼의 안정성을 높여줍니다. 새로고침하시면 매번 달라지는 CSRF값을 보실 수 있습니다. 그리고 CSRF를 사용하는 경우 CSRF값이 없는 폼 전송은 위험한 요청으로 생각하고 폼을 받아들이지 않습니다.(즉, 로그인이 되지 않습니다.) 따라서 우리는 _csrf라는 것도 함께 전송해 줘야 합니다. 따라서 메인 화면을 먼저 가져와 _csrf필드를 가져오고 로그인을 해야 합니다.
이전 클리앙은 CSRF검증이 없었습니다. 이번 업데이트를 하면서 클리앙의 보안이 전반적으로 올라갔습니다. 좋은 변화입니다!
다음으로는 auth.login()이라는 함수를 살펴봅시다. 함수를 살펴보면 그냥 입력 유무만 확인하는 심플한 함수입니다. 사실 이것보다 더 길지만, 실제로 login함수에서 사용되는 코드 부분은 이부분이 전부이기 때문에 뒷부분을 잘랐습니다.
1 | function Auth() { |
위 자바스크립트 코드에서 알게된 것은 아이디와 비밀번호 폼에 빈칸이 없다면 POST방식으로 https://www.clien.net/service/login에 폼을 전송해 로그인을 한다는 것입니다.
한번 이 주소에 폼 값들만 넣어서 전송해 봅시다.
1 | # parser.py |
이런! 404가 나와버렸네요. 제대로 로그인이 되지 않은 것 같아요. 아마 _csrf값이 없어서가 아닐까요?
1 | > python parsing.py |
그렇다면 코드를 조금 더 수정해 봅시다. 우선 클리앙 공식 홈페이지에 들어가 form에 들어있는 _csrf값을 가져와 봅시다.
1 | # parser.py |

와우! 200이 나온걸 보니 성공적으로 로그인이 된 것 같아요.
진짜 데이터를 가져와봅시다
이제 우리 코드를 좀 더 멋지게 만들어 봅시다. 로그인이 실패한 경우 Exception을 만들고, 성공일 경우에는 회원 장터의 게시글을 가져와봅시다.

위 스크린샷처럼 오른쪽 버튼을 누르고 Copy > Copy selector를 눌러주면 #div_content > div.post-title > div.title-subject > div라는 CSS Selector가 나옵니다. 이 HTML문서에서 이 제목만을 콕 하고 찾아줍니다.

본문도 같은 방식으로 찾아줍시다. 다만 p태그가 아니라 글 전체를 담고있는 #div_content > div.post.box > div.post-content > div.post-article.fr-view을 가져와봅시다.
1 | # parser.py |
코드를 실행해 봅시다.

잘 가져옵니다 :)
그러나, 위 코드가 안먹힌다면?
일부 사이트의 경우 프론트 브라우저 단에서 ID와 PW를 이용해 암호화된 전송값을 보내는 경우가 있습니다.(대표적으로 네이버가 이렇습니다.) 또한, SPA등으로 인해 PageSource을 가져오는 것이 불충분한 경우가 자주 있습니다.
물론 오늘처럼 JS파일을 분석해 수동으로 data에 넣어주는 방법도 있지만, 브라우저를 직접 다뤄서 사람이 로그인하듯 크롤링을 해보면 어떨까요?
다음 포스팅에서 좀 더 간편히 실제 브라우저(혹은 Headless브라우저)를 이용해 로그인부터 크롤링까지, 간편하게 해보는 방법을 알아봅시다.
다음 가이드: 나만의 웹 크롤러 만들기(3): Selenium으로 무적 크롤러 만들기
업데이트 후기
2017년 7월 12일, 올해 초(1월 20일)에 작성한 인기 크롤링글 대상인 클리앙이 바뀌어 업데이트가 필요했습니다. 사실 예전 코드를 업데이트 하는 것도 사실상 새 글을 쓰는 것과 같은 시간과 노력이 듭니다. 하지만 오래된 정보를 두는 것보다 새로운 정보를 두는 것이 낫다고 생각해 업데이트를 했으나..!
클리앙을 이용하는데 덧글 쓰기/글 쓰기 빼고 글을 읽는 것에 제한은 회원장터조차도 제한이 없어졌더군요. (눈물)
그래도 이 가이드를 기반으로 다른 사이트 로그인 하는데 조금 더 쉬워지기를 바랍니다.